
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- pandas
- Python
- androidStudio
- Compose
- GitHub
- textfield
- 암호학
- Hilt
- 코드포스
- Gradle
- Kotlin
- relay
- Codeforces
- boj
- ProGuard
- 쿠링
- 백준
- Coroutine
- Coroutines
- architecture
- android
- MyVoca
- NGINX
- livedata
- Rxjava
- 프로그래머스
- MiTweet
- 코루틴
- AWS
- TEST
- Today
- Total
이동식 저장소
자료구조 (2) 본문
Graph
그래프란 하나 이상의 정점이 0개 이상의 간선으로 이어진 것을 말한다.

간선은 양방향일 수도, 단방향일 수도 있다. 간선이 단방향이라면 간선을 통해 한쪽 방향으로만 이동할 수 있으며, 반대로는 이동할 수 없다.
간선에는 가중치가 있을 수도 있다. 일반적으로 가중치란 간선을 지나가는 비용 또는 정점 간의 거리를 의미한다.
그래프와 관련된 알고리즘으로는 최단 거리 알고리즘과 SCC 등이 있다.
Tree
생각해 보니 Heap보다 Tree를 먼저 정리해야 했는데... 뭐 어쩔 수 없지.
사이클이 없는 그래프를 Tree라고 부른다. 사이클이란 정점에서 출발하여 서로 다른 간선을 지나 자기 자신으로 돌아오는 경로이다.

트리의 맨 위에 있는 노드를 루트 노드라고 한다. 반대로 맨 밑에 있는 노드를 리프 노드라고 부른다. 이름대로라면 뿌리가 맨 위에 있는 요상한 구조 같지만, 대충 나무를 뒤집은 형태라고 생각하자.
트리에 속한 정점의 level은 루트와 정점 사이의 거리이다. 이렇게 정의하면 루트의 level은 0이 되지만, 편의상 루트의 level을 1로 놓고 계산할 수도 있다.
트리에는 몇 가지 중요한 성질이 있다.
- 사이클이 없다.
- 트리의 노드가 $N$개라면 간선은 $N-1$개이다.
- 임의의 두 노드 사이의 경로가 존재하며, 또한 유일하다.
두 노드 간의 경로가 유일한 이유는 1) 모든 정점이 연결되어 있기 때문에 두 노드 간의 경로가 항상 존재하고, 2) 사이클이 없기 때문에 오직 하나의 경로만이 존재하기 때문이다.
트리 순회
트리의 순회란 트리의 정점을 빠트리지 않으면서 단 한 번만 방문하는 것을 말한다. 순회 방법에는 DFS와 BFS 두 가지가 있다.
DFS(Depth First Search)는 자식이 존재하는 한 계속 깊숙히 들어가는 탐색 방법이다. 위의 트리를 다시 한 번 보자.
이 트리를 DFS로 탐색해 보자. 루트 노드인 2에서 시작하여 7을 탐색하고, 7의 자식 2를 탐색한다. 2는 자식이 없으므로 7로 이동해서 다른 자식 6을 탐색한다. 6의 자식 5를 탐색하고, 5는 자식이 없으므로 6으로 올라와 11로 다시 들어간다.
이렇게 깊이 내려가는 탐색 방식을 DFS라고 한다.
반면 BFS(Breadth First Search)는 같은 레벨의 노드를 먼저 탐색한다. 루트인 2에서 시작하여 다음 레벨인 7, 5를 탐색하고, 그 다음 레벨인 2, 6, 9를 탐색하는 식이다. DFS는 끝까지 들어가는 방법이고, BFS는 파동이 퍼져나가듯이 탐색하는 방식이라고 기억하면 좋다.
Binary Tree
각 노드의 자식이 최대 2개인 트리를 이진 트리라고 한다. 이진 트리를 사용하여 힙을 구현할 수 있다. 힙도 각 노드의 자식이 최대 2개이기 때문이다.
이진 트리를 탐색하는 방법은 다음과 같다.
- 전위 순회: 자신 → 왼쪽 자식 → 오른쪽 자식 순으로 탐색한다.
- 중위 순회: 왼쪽 자식 → 자신 → 오른쪽 자식 순으로 탐색한다.
- 후위 순회: 왼쪽 자식 → 오른쪽 자식 → 자신 순으로 탐색한다.
이진 트리 중에서도 몇몇 조건을 만족하는 트리에는 특별한 이름이 붙어 있다.
포화 이진 트리 (Full Binary Tree)
리프 노드를 제외한 모든 노드가 자식을 2개씩 가지는 이진 트리이다. 반드시 2개를 가진다는 특징이 있다.
루트의 레벨을 0이라고 하면, 레벨 $i$에는 $2^{i}$개의 정점이 존재한다. 따라서 높이가 $k$인 포화 이진 트리에는 $2^{k}-1$개의 정점이 존재한다.
완전 이진 트리 (Complete Binary Tree)
완전 이진 트리는 마지막 레벨을 제외한 모든 레벨이 꽉 찬 이진 트리를 말한다. 포화 이진 트리는 완전 이진 트리이다.

균형 이진 트리 (Balanced Binary Tree)
모든 리프 노드의 깊이 차이가 최대 1인 트리를 균형 이진 트리라고 한다.

사칙 연산식을 후위 표기법과 일치하는 이진 트리로 만들고, 트리를 전위 순회하면 식을 계산할 수 있다.
Binary Search Tree
Binary Search 알고리즘은 정렬된 배열에서 값을 로그 시간에 찾는 알고리즘이다. 대신 배열에서 값을 삽입하거나 삭제하는 알고리즘은 아니다. 그건 배열의 영역이다.
LinkedList는 반대로 값의 삽입과 삭제에 특화된 자료구조이다. 탐색 시간을 고려하지 않으면 상수 시간에 값을 삽입하고 삭제할 수 있다. 하지만 값을 찾는 데에는 선형 시간이 걸린다.
Binary Search Tree(BST)를 사용하면 값을 빠르게 수정하면서 동시에 빠르게 검색할 수 있다.
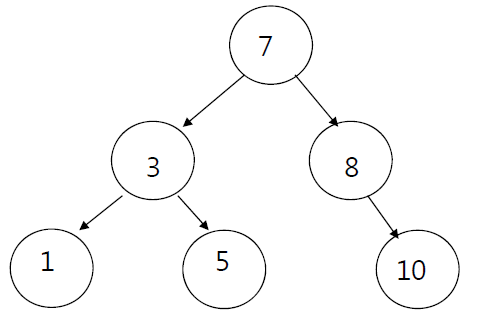
BST는 이진 트리의 일종으로, 자료의 삽입, 삭제, 탐색을 모두 로그 시간에 수행할 수 있다.
자신의 한쪽 자식은 자신보다 크고, 다른 쪽 자식은 자신보다 작은 특징이 있다. 보통 자신보다 작은 값은 왼쪽 서브 트리에, 자신보다 큰 값은 오른쪽 서브 트리에 저장한다.

BST에는 중복된 값을 넣지 않는 것이 좋다. 쓸데없이 검색 시간만 늘리기 때문이다. 값을 중복하여 넣고 싶다면 차라리 노드에 count 변수를 추가하자.
BST를 중위 순회하면 정렬된 순서를 얻을 수 있다. 자신보다 작은 원소를 왼쪽에 놓았다면, BST를 중위 순회하여 오름차순으로 정렬된 결과를 얻을 수 있다.
탐색
정수 $x$를 탐색한다고 가정하자. 루트에서 탐색을 시작한다.
$x$가 루트보다 크다면 오른쪽 서브 트리에서 $x$를 찾아야 한다. 반대로 $x$가 루트보다 작다면 왼쪽 서브 트리에서 $x$를 찾아야 한다. 이처럼 노드의 값과 $x$를 비교하여 왼쪽 또는 오른쪽으로 이동하면 된다. 더 이상 탐색할 수 없는 경우 $x$가 존재하지 않는 것이다.
한쪽 서브 트리를 아예 배제하는 특성 덕분에 탐색 시간이 대폭 줄어든다. 보통 로그 시간에 값을 탐색할 수 있지만, BST가 한쪽으로 쏠려 있는 경우 선형 시간이 걸릴 수도 있다.
삽입
BST에서의 삽입 연산은 Heap과 유사하다. 일단 리프 노드에 붙인 다음, BST의 성질을 만족하지 않는다면 자신을 루트와 교환한다. BST의 성질을 만족할 때까지 계속 교환하면 삽입이 완료된다.
삽입 연산 역시 로그 시간에 수행된다. 마찬가지로 트리가 일직선으로 쏠려 있는 최악의 경우 선형 시간까지 느려질 수 있다.
삭제
삭제 연산은 약간 복잡하다. 값을 삭제했더니 BST의 조건이 깨질 수도 있기 때문이다. 자식 노드의 나누어 생각해 보자.
우선 삭제할 노드에 자식 노드가 없는 경우에는 그냥 삭제하면 된다. 끝!
다음으로 자식 노드가 하나 있는 경우에는 자신의 루트와 자식을 연결하면 된다. BST의 성질에 의해 자신을 루트로 하는 서브 트리의 모든 값은 자신의 부모보다 작다.

그림에서는 왼쪽 자식을 삭제했지만, 오른쪽 자식을 삭제하는 경우에도 동일하게 BST의 성질이 계속 유지된다.
마지막으로 자식 노드가 2개 있는 경우에는 어떻게 해야 할까?

삭제할 값의 왼쪽 서브 트리 중 최댓값을 predecessor, 오른쪽 서브 트리 중 최솟값을 successor라고 하자. 삭제할 값의 위치에 predecessor 혹은 successor를 덮어쓰고(이때 실질적으로 값이 삭제됨), 덮어쓴 값을 삭제하면 BST의 성질을 유지할 수 있다.
successor의 자식은 많아야 하나이다. 자식이 둘이라면 자신보다 작은 값과 큰 값이 모두 존재한다는 말인데, 그러면 successor보다 작은 값이 존재한다는 말이므로 successor의 정의에 모순이다. 마찬가지로 predecessor의 자식도 많아야 하나이다.
삭제 과정을 정리하면 다음과 같다.
- 삭제할 노드의 predecessor와 successor를 복사한다.
- 삭제할 노드에 predecessor 또는 successor를 복사한다. (이건 구현하기 나름이다)
- 복사한 값을 삭제한다.
이렇게 하면 BST의 성질을 깨트리지 않으면서 노드를 가장 쉽게 삭제할 수 있다.
가장 오래 걸리는 마지막 경우를 기준으로 삭제 연산의 시간복잡도를 계산하면, 1번 과정은 탐색과 같고, 2번과 3번 과정은 상수 시간에 수행할 수 있다. 따라서 삭제 연산의 시간복잡도는 트리의 높이에 선형으로 비례한다. 마찬가지로 트리의 균형이 잘 잡혀있다면 로그 시간에, 트리가 일직선으로 쏠려 있다면 선형 시간에 수행될 것이다.
쏠려 있다?
루트보다 작은 값 또는 큰 값만 계속 삽입되면 트리가 한 쪽으로 쏠리게 된다. 구현 방법에 따라 쏠리는 것은 아니다.

AVL Tree를 사용하면 트리의 균형을 엄격하게 맞출 수 있다. AVL Tree에 대해서는 다음 글을 참고하자.
AVL tree · ratsgo's blog
이번 글에서는 AVL 트리에 대해 살펴보도록 하겠습니다. 이 글은 고려대 김황남 교수님 강의와 위키피디아를 정리하였음을 먼저 밝힙니다. 파이썬 코드는 이곳을 참고하였습니다. 그럼 시작하겠
ratsgo.github.io
Set, Map
Set은 중복된 원소를 허용하지 않는 집합 자료구조이고, Map은 중복되지 않은 key에 하나의 value를 짝지어 저장하는 자료구조이다. 삽입, 탐색, 삭제 모두 로그 시간에 수행할 수 있다. 보통 트리를 사용해 구현되며, cpp에서는 Red-Black Tree로 구현된다. RB Tree는 아래에서 다시 살펴보겠다.
원소가 정렬되는 순서는 중요하지 않다. 물론 내부적으로 정렬된 순서로 저장되긴 하지만, 개념상 정렬을 위해 사용하는 자료구조와는 거리가 멀다. 수를 삽입하면서 정렬하고 싶다면 Heap을 사용해야 한다.
그런데 원소가 중복되지 않는다는 걸 어떻게 알 수 있을까? 많은 언어에서 중복을 처리하는 자료구조를 사용하려면 두 값을 비교하는 ``compare`` 함수를 정의해야 한다. 정수나 문자열은 언어에 내장된 비교함수를 사용할 수도 있지만, 일반적인 객체를 비교할 때에는 직접 비교 함수를 제공해야 한다.
``compare(a, b)``는 언어에 따라 정수 또는 bool을 반환해야 한다. 정수를 반환해야 한다면 ``a``의 순서가 ``b``보다 먼저라면 음수를, ``b``가 ``a``보다 먼저라면 양수를, 둘의 순서가 같다면 0을 반환하면 된다. bool을 반환해야 한다면 ``a``가 먼저일 때 ``true``를 반환하면 된다.
``compare`` 함수를 사용하여 ``a``와 ``b``가 같은 지 검사하려면 ``compare(a, b)``와 ``compare(b, a)``가 둘 다 false 또는 false로 해석될 수 있는 값이어야 한다. 비교의 교환법칙이 성립하지 않는 자료형도 존재하기 때문에 순서를 바꿔서 비교해봐야 한다.
이제 두 값이 같은지 검사할 수 있으므로, 어떤 값 $x$가 Set 또는 Map의 모든 값과 다르다면 $x$는 존재하지 않는 값이라고 판정할 수 있다.
참고로 cpp에는 중복된 원소를 허용하는 ``std::multiset``과 ``std::multimap``이 있다. 비교 연산자만 수정하면 구현할 수 있다.
HashTable
해시 함수란 데이터를 임의의 값으로 매핑(mapping)하는 함수이다. 해시 테이블은 데이터를 해시 값으로 매핑하여 저장하는 자료구조이다. 그래서 해시 테이블의 핵심은 해시 함수라고 할 수 있다. 해시값을 원본 데이터로 복원할 수는 없지만, 오히려 그렇기 때문에 데이터를 효율적으로 저장할 수 있는 것이다.
해시 값은 상수 시간에 계산할 수 있어야 하며, 하나의 값에 대해 항상 같은 해시 값을 반환해야 한다. 해시가 상수 시간에 계산되기 때문에 해시 테이블의 삽입 연산도 상수 시간에 수행된다.
해시 함수는 서로 다른 값에 대해 최대한 다른 해시값을 반환해야 한다. 물론 비둘기집의 원리에 의해 데이터가 많아지면 어쩔 수 없이 해시값이 겹칠(=충돌할) 수 있다. 충돌 문제가 있음에도 해시 테이블을 사용하는 이유는 복잡한 데이터를 간단한 해시 값으로 바꿔 저장할 수 있기 때문이다.
그런데 해시 값이 충돌하면 어떻게 해야 할까? 대략 다음과 같은 해결 방법이 있다.
- 체이닝: 해시 값이 같은 원소들을 (연결)리스트로 저장하는 방식이다. 가장 간단한 해결법이지만, 메모리 사용량이 많아질 수 있다.
- Open addressing: 해시가 충돌했을 때 바로 옆 칸에 저장하는 방식이다. 예를 들어 해시 값 2가 충돌했다면, 대신 3에 저장해볼 수 있다. 3도 이미 존재한다면 4에 저장해볼 수 있다.
- Quadratic probing: 기본적으로 Open addressing과 동일하지만, 한 칸씩 이동하면서 빈 공간을 찾는 대신 $i^{2}$만큼 이동하면서 빈 공간을 찾는다. 그러니까 1칸, 4칸, 9칸, ... 이렇게 이동하면서 빈 공간을 찾는 것이다.
- 이중 해시: Open addressing과 Quadratic probing 방법은 해시값이 같을 때 항상 같은 인덱스에서 빈 공간을 찾는다. 이렇게 하면 데이터가 뭉쳐서 존재하는 클러스터 현상이 발생할 수 있다. 따라서 데이터를 최대한 분산시키기 위해 충돌이 발생했을 때 몇 칸 이동하여 빈 공간을 찾을 지 계산하는 두 번째 해시 함수를 정의할 수 있다. 두 번째 해시 역시 원본 값을 입력받아야 한다.
B Tree
이진 트리는 노드 하나당 자식을 최대 2개까지만 가질 수 없고, 트리의 균형이 맞지 않으면 연산 성능이 선형 시간까지 느려질 수 있다. 하지만 균형만 맞다면 검색, 삽입, 삭제를 모두 로그 시간에 처리할 수 있기 때문에 이진 트리를 개선한 자료구조가 많이 개발되었다. B tree도 이진 트리를 응용한 자료구조이다.
B tree는 하나의 노드가 2개 이상의 자식을 가질 수 있고, 하나의 노드 안에 여러 개의 값을 정렬하여 저장한다. 드 안에 최대한 많은 값을 저장하면 접근 횟수와 트리의 높이를 줄이고, 균형을 맞추는 밸런싱을 덜 수행하면서 전체 연산 시간을 줄일 수 있다.
노드의 크기를 늘리는 아이디어는 보조기억장치의 구조에서 착안되었다. 하드디스크나 SSD는 블럭 단위로 데이터를 읽는데, 블럭 크기가 10바이트라면 2바이트를 읽건 10바이트를 읽건 동일한 시간이 소요된다. 따라서 노드 크기를 늘리면 동일한 시간에 더 많은 데이터를 읽을 수 있게 된다. 이런 특성 때문에 데이터베이스나 파일 시스템에서 흔히 사용된다.

B 트리의 성질
하나의 노드에 최대 $M$개의 자료를 저장할 수 있다고 하자.
- $N$개의 값을 저장하는 노드의 자식은 $N+1$개이다.
- 노드 내부에서는 값이 정렬되어 저장된다.
- 중복된 값이 존재할 수 없다.
- 루트 노드는 적어도 2개의 자식을 가져야 한다.
- 루트를 제외한 모든 노드는 적어도 $M/2$개의 자료를 저장해야 한다.
- 모든 리프 노드가 동일한 레벨에 위치한다.
이 외에도 자식 노드의 값을 제한하는 조건도 있다. 위 그림에서 7 왼쪽에 연결된 자식은 7보다 작은 값만 저장하며, 7과 16 사이에 있는 자식에는 7보다 크고 16보다 작은 값만 저장될 수 있다.
B 트리 이외에도 B* 트리, B+ 트리 등의 변종이 있는데, 여기서 정리하기에는 너무 과한 것 같다. 나중에 여유있을 때 정리해 보겠다.
Red-Black Tree
Red-Black Tree 또는 RB Tree는 Binary Search Tree의 특수한 형태로, 스스로 균형을 맞추는 자가 균형 이진탐색트리이다.

꽤 복잡한 자료구조이지만, 최악의 경우에도 꽤 빠른 동작을 보여준다. 일단 기본적으로 BST이기 때문에 삽입, 삭제, 탐색을 모두 로그 시간에 처리할 수 있다. 로그 시간 자료구조 중에서도 빠른 편이라고 이해하면 되겠다. 최악의 경우에도 빠른 실행을 보장하기 때문에 프로그래밍 언어에서 Set이나 Map 등은 RB Tree로 구현된 경우가 많다. 예를 들어 cpp.
RB Tree는 이진 탐색 트리의 조건을 만족하는 동시에, 다음의 조건을 추가로 만족한다.
- 모든 노드는 검은색 혹은 빨간색이다.
- 루트는 항상 검은색이다.
- 모든 리프 노드(그림에서 NIL)는 검은색이다. 참고로 RB 트리에서 NIL 노드는 값을 가지지 않으며 트리의 끝을 나타내는 역할만 한다. NIL 노드 덕분에 RB 트리가 완전 이진 트리의 조건을 만족할 수 있다.
- 빨간색 노드의 모든 자식은 검은색이다. 즉 빨간색 노드가 연속으로 존재할 수 없으며, 빨간색 노드의 부모는 언제나 검은색 노드이다.
- 어떤 노드로부터 자신의 하위 리프 노드에 도달하는 모든 경로에는 항상 같은 개수의 검은색 노드가 존재한다.
이 조건을 만족함에 따라 RB 트리는 가장 중요한 한 가지 성질을 보인다.
루트에서 가장 먼 리프 노드까지의 거리는 항상 루트에서 가장 가까운 리프 노드의 거리의 2배보다 작다.
최단 경로가 $N$개의 검은색 노드로만 이루어져 있을 때, 4번 조건에 의해 최장 경로에는 $N-1$개 이하의 빨간색 노드가 존재한다. 따라서 최장 경로의 길이는 항상 $2N-1$ 이하이고, 최단 경로와 최장 경로의 비는 항상 1:2 이하이다. 최단 경로에 빨간색 노드가 존재한다면 이 비율은 더 떨어질 것이다.
그래서 RB 트리를 대략(roughly) 균형 잡힌 BST라고 부르는 것이다. 완벽하게 균형 잡힌 트리는 아니지만(사실 그런 트리를 유지하는 데에도 시간이 많이 든다), 성능을 보장할 수 있을 정도로 균형잡혀 있기 때문이다.
TMI: 써놓고 보니 굉장히 엄숙한 자료구조 같지만, 사실 위에서 소개한 AVL 트리가 더 엄격하게 균형잡혀 있다. 반대급부로 AVL 트리는 균형 잡는 연산을 더 많이 해야 한다. 균형 잡는 시간이 절대 만만하지 않다는 사실..
연산
탐색은 일반적인 이진 탐색 트리처럼 탐색하면 된다. 사실상 코드를 복붙해도 되는 수준. 하지만 삽입 및 삭제 연산은 꽤 복잡하다. 여기서 정리하기에는 여백이 부족하므로, 위키피디아의 글을 참고하자.
레드-블랙 트리 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 레드-블랙 트리(red-black tree)는 자가 균형 이진 탐색 트리(self-balancing binary search tree)로서, 대표적으로는 연관 배열 등을 구현하는 데 쓰이는 자료구조다. 1978년
ko.wikipedia.org
Trie
문자열을 효율적으로 저장하는 자료구조이다. 가장 긴 문자열의 길이가 $L$인 문자열 $N$개를 배열에 저장했을 때 내가 원하는 문자열이 존재하는지 탐색하는 연산의 시간복잡도는 $O(NL)$이다. 물론 정렬한 뒤 이진 탐색해도 되지만, 정렬하는 데 $O(NL \log L)$의 시간이 걸린다.
Trie를 사용하면 문자열을 더 효율적으로 탐색할 수 있다. 일단 Trie는 이름에서도 알 수 있듯이 트리 형태로 문자열을 저장한다.

뭔가 복잡해 보이지만, 차분히 설명을 읽어 보자.
트리의 정점(간선으로 설명하는 사람도 있다)은 하나의 문자를 의미한다. Trie에서 문자열은 경로로 표현된다. 예를 들어 문자열 ``abc``는 정점 ``a``, ``b``, ``c``를 지나는 경로로 표현된다.
Trie가 효율적인 이유는 문자열에서 중복되는 부분을 하나의 경로로 표현할 수 있기 때문이다. ``abc``를 저장한 후 ``abd``를 저장하고 싶다면, ``ab`` 부분은 그대로 두고 ``d``로 가는 경로만 새로 만들면 된다.

이처럼 Trie는 경로의 중복을 최대한 없애는 자료구조이다. 물론 모든 경로가 겹치지 않는다고 해도 길이가 $L$인 문자열을 $O(L)$ 시간에 검색할 수 있으니 상관없다. 문자열을 찾는 최선의 시간이 선형 시간이므로 Trie는 문자열을 찾는 최선의 자료구조 중 하나인 셈이다.
그런데 위의 그림을 잘 보면, 루트 → ``a`` → ``b`` 경로가 있긴 하지만 문자열 ``ab``를 저장한 적은 없다. 단순히 지나가는 정점과 문자열의 끝을 나타내는 노드를 구분할 필요가 있다. 보통은 노드에 bool flag를 하나 정의하여 나타낸다. 또는 정수형 변수를 사용하여 문자열이 저장된 횟수를 나타낼 수도 있다.

