
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- boj
- Coroutines
- MyVoca
- Codeforces
- architecture
- Python
- TEST
- Hilt
- 코루틴
- MiTweet
- GitHub
- Gradle
- 암호학
- android
- NGINX
- relay
- pandas
- 코드포스
- Coroutine
- AWS
- 프로그래머스
- Kotlin
- Compose
- 쿠링
- 백준
- Rxjava
- androidStudio
- textfield
- ProGuard
- livedata
- Today
- Total
이동식 저장소
Pandas (1) 본문
Pandas는 구조화된 데이터의 처리를 지원하는 Python 라이브러리로, Python계의 엑셀이라고도 불립니다. 엑셀처럼 데이터를 정리하여 보여준다는 뜻이죠.

그럼 이제부터 Pandas를 이용하여 데이터를 읽고 처리하는 방법을 알아보도록 합시다.
Import
Pandas 역시 외부 라이브러리이므로 import를 해야 사용할 수 있습니다. 이때 pd라는 축약어로 import하는 습관이 널리 퍼져있습니다.
import pandas as pd이 글에서도 pd라는 명칭을 사용하도록 하겠습니다.
데이터 불러오기
데이터는 .csv 파일 또는 웹으로부터 불러올 수 있습니다. 데이터를 불러오기 위해서는 read_csv()를 호출하면 됩니다.
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data' #Data URL from web
# data_url = './housing.data' #Data URL from file
df_data = pd.read_csv(data_url, sep='\s+', header = None)매개변수 sep는 'separator'를 의미합니다. 문자열을 split할 때의 delimiter와 같은 역할을 합니다. 별다른 조건이 없다면 탭 문자를 의미하는 '\s'로 하도록 합시다. 뒤에 붙은 +는 정규 표현식에서 "1개 이상"을 의미하는 표현입니다. 잘 모르겠다면 그냥 넘어가도 됩니다.
데이터를 불러왔으니 한번 출력해 봅시다.
print(df_data.head()) # print some head values
print(df_data.values) # get values as numpy array
print(type(df_data.values))
스프레드시트처럼 잘 정렬되어 출력되었습니다. head()는 데이터의 처음 몇 개를 보여주는 함수이며, 매개변수를 줘서 출력할 개수를 지정할 수 있습니다. 기본값은 5개입니다.
데이터 객체의 values 변수는 데이터를 numpy array로 반환합니다.
Series
위에서 본 데이터 전체를 Pandas에서는 "DataFrame", 줄여서 df라고 합니다. DataFrame의 각 열은 Series라고 부릅니다. 즉 우리가 위에서 출력한 df는 13개의 Series로 구성되어 있는 것입니다. 행(row)을 부르는 이름은 tuple, row 등으로 다양합니다. 편한 대로 부르도록 합시다.
Series를 간단하게 재정의하면 "column vector object" 정도 되겠습니다. 직접 객체를 만들어 봅시다.
list_data = [1, 2, 3, 4, 5]
example_obj = pd.Series(data=list_data) # make series from list
print(example_obj)
Series이기 때문에 (index, value) 쌍이 세로로 출력됩니다. 마지막에 데이터 타입이 출력된 모습도 확인할 수 있습니다.
위에서는 인덱스가 0부터 시작합니다. 그러나 인덱스가 1부터 시작해야 하는 경우도 있고, 문자열로 지정해야 할 때도 있습니다. 이런 상황에는 인덱스를 바꿀 수 있습니다.
더불어 Series에 이름도 붙여줄 수 있습니다. 한번 보도록 합시다.
index_data = ['a', 'b', 'c', 'd', 'e']
example_obj2 = pd.Series(data=list_data, index=index_data, name="example object 2") # change index, name
print(example_obj2)
인덱스와 series name이 지정된 모습을 확인할 수 있습니다.
Series의 원소에 접근하려면 인덱스를 이용하면 됩니다. 이때는 그냥 리스트 접근하듯이 하면 됩니다.
# indexing!
print(example_obj[1])
print(example_obj2['a'])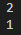
DataFrame
Series가 여러 개 모이면 DataFrame이 됩니다. 2차원 배열이라고 생각하면 쉽습니다. 이때 각 Series의 데이터 타입은 다를 수 있으며, Series를 추가하고 삭제할 수도 있습니다. 이 글에서는 줄여서 df로 쓰겠습니다.
DataFrame을 만들고 출력해 봅시다.
# Dataframe: set of series; Numpy array-like
# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
df = pd.DataFrame(raw_data, columns=[
'first_name', 'last_name', 'age', 'city', 'older'])
print(df)
raw data를 기반으로 df를 만들었습니다. Series 이름에 맞게 데이터가 잘 들어갔네요. 그런데 older는 뭐죠? raw data에 없는 값을 가지고 series를 만들라고 하네요. 이런 경우에는 NaN이 들어갑니다.
값을 찾을 수 없습니다.
NaN은 대략 이런 의미입니다. 이런 경우에는 데이터를 추가하던지, column을 지우던지 해야겠죠.
Column에 접근하기
df의 각 series에 접근하는 방법은 두 가지가 있습니다.
# get column
print(df.first_name)
print(df['first_name'])
각자 편한 방법대로 접근하면 되겠습니다. 저는 리스트처럼 접근하는 두 번째 방법을 쓰도록 하겠습니다.
loc(), iloc()
column 대신 각 row에 접근하고 싶다면 loc() 또는 iloc()을 쓰면 됩니다.
# get location(tuple!): loc(index name), iloc(index number)
print(df.loc[1])
print(df.iloc[2])
loc은 인덱스 이름, 그러니까 위에 보이는 인덱스 값을 가지고 접근합니다. 즉 index==1을 만족시키는 row를 출력하는 겁니다.
반면 iloc은 인덱스 값이 아닌 "순서"를 기준으로 합니다. 예제를 다시 한번 가져와 봅시다.
두 번째 row에는 인덱스 'b'가 부여되어 있습니다. 따라서 loc('b')를 하면 2를 얻을 수 있습니다. 만약 iloc으로 이 데이터를 얻고 싶다면, 이 값이 위에서부터 몇 번째에 있나 봐야 합니다. 두 번째에 있네요. 따라서 iloc(1)을 하면 같은 값을 얻을 수 있습니다.
Slice
Slice하여 여러 row를 얻을 수도 있습니다. iloc, loc 모두 가능합니다.
# can be sliced
print(df.loc[1:])
Assign datas
비어있던 older에 값을 넣어 봅시다. 30살이 넘으면 True, 그렇지 않으면 False로 값을 넣고 싶은데, 간단한 조건식 한 줄이면 됩니다.
# assign new data by condition
df.older = df.age > 30
print(df)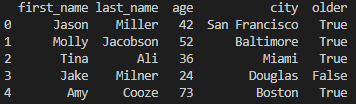
Drop column
30대 개발자분들이 보면 화 내실 것 같으므로 older column을 지우도록 하겠습니다.
# drop column
del df['older']
print(df)
참 쉽죠?
Selection
column name으로 데이터를 선택해 봅시다.
# selection
print(df['age'].head(3)) # gets from single column, start from head
print(df[['first_name', 'age', 'city']].head(3)) # gets from columns
첫 번째 줄에서는 age column에서 처음 3개의 데이터를 가져왔습니다. 별로 문제될 건 없어 보입니다.
두 번째 줄은.. 리스트가 들어가 있네요. column name으로 이루어진 리스트를 주면 그 column들을 얻을 수 있습니다. 그런데 어째 읽기가 영 불편하므로 주의하도록 합시다.
Selection with index number
column을 지정하지 않고 사용하는 index는 index number(iloc!)를 의미합니다.
# no column name: index number indicates row
print(df[:3])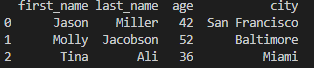
column 이름을 지정하여 해당 column에서만 데이터를 가져올 수도 있습니다.
# select series
age_series = df['age']
print(age_series[:3])
Boolean Index?
numpy에서의 boolean index를 기억하고 계실 겁니다. 조건에 맞는 값의 index만 얻어오는 방법이었죠? series에서도 같은 방법을 적용할 수 있습니다. 예를 들어 40살 미만인 나이를 가져오고 싶다면
# boolean index
print(age_series[age_series < 40])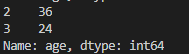
이렇게 하면 됩니다. 출력되는 걸 보니 series가 반환되나 봅니다. 인덱스뿐 아니라 값도 반환되었네요.
Index를 바꾸고 싶다!
1부터 시작하는 index를 부여할 수도 있지만, 각 데이터의 고유한 값으로 index를 지정하고 싶을 때도 있습니다(hash table의 key처럼?). df에서는 어떤 column을 index로 사용할 수 있습니다.
# change index
df.index = df['age']
del df['age'] # remove redundancy
print(df)
age가 인덱스가 되었습니다. 두 번째 줄에서 age를 지운 것은, age를 index로 지정해도 여전히 age column이 남아 있기 때문입니다. 데이터 중복을 피하기 위해 column을 삭제했습니다.
다양한 Selection 방법
데이터를 선택할 때 column과 row를 모두 지정할 수 있습니다. column과 row 모두 각각 name 또는 number로 지정할 수 있지요. 예시를 보면서 이해합시다.
print(df[['first_name', 'city']][:2]) # column name, index number
print(df.loc[[36, 73], ['first_name', 'last_name']]) # column name, index name
print(df.iloc[:2, :2]) # column number, index number
한 줄씩 뜯어서 읽어보면 어렵지 않습니다. 직접 분석해보시기 바랍니다.
Restore index
나이로 장난치는 건 그만 하고, 다시 번호를 붙여주도록 합시다.
# index reset
df.index = list(range(5))
print(df)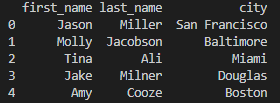
Drop row
위에서 column을 지우는 방법을 알아봤습니다. row를 지우는 방법은 없을까요? index number를 이용하여 row를 제거할 수 있습니다.
# drop row
print(df.drop(1)) # by index number
print(df) # is it dropped?
drop할 때는 지워져 있더니, 갑자기 다시 등장했습니다. 이게 뭐죠? 이것은 pandas가 데이터를 다루는 원칙과 관련된 문제입니다.
pandas는 원본 데이터를 훼손하고 싶지 않아 합니다. 즉, df에 데이터를 넣거나 지우는 연산은 전부 "복사본"을 반환합니다. 원본을 남겨놓고 싶어하기 때문이죠.
pandas의 만류에도 불구하고, 원본 데이터를 지워버리겠다면 어쩔 수 없죠. 매개변수 inplace를 True로 설정하면 됩니다.
df.drop(1, inplace=True) # want to erase permanently? set inplace "True"
print(df)
Operations
연산이 가능한 자료형(int64, float32 등등)으로 이루어진 Series는 numpy array처럼 연산 가능합니다. 이때 인덱스가 같은 것끼리만 연산한다는 점을 기억하시기 바랍니다. 매칭되는 index가 없다면 연산은 NaN을 반환합니다.
# series operation(broadcasting): operate with same index
# if no same index: return NaN
s1 = pd.Series(range(1, 6), index=list('abcde'))
s2 = pd.Series(range(5, 11), index=list('bcedef'))
print(s1.add(s2))
print(s1+s2)
s2에 인덱스 'a'가 없기 때문에 result['a']=NaN입니다.
DataFrame끼리도 연산할 수 있습니다. 단 column name과 index name을 모두 따진다는 점을 잘 기억합시다.
# dataframe operation: considers both column and index
df1 = pd.DataFrame(np.arange(9).reshape(3, 3), columns=list('abc'))
df2 = pd.DataFrame(np.arange(16).reshape(4, 4), columns=list('abcd'))
print(df1+df2)
df1에는 4번째 row가 없고, index 'd'도 없으므로 NaN이 채워져 있네요.
NaN이 불편하다면 '기본값'을 지정할 수 있습니다. '기본값'이란 해당 위치의 값이 없을 때(ex: df1[3]['a']) 대신 반환되는 값입니다.
# no matching column & index -> NaN or fill_value
print(df1.add(df2, fill_value=0))
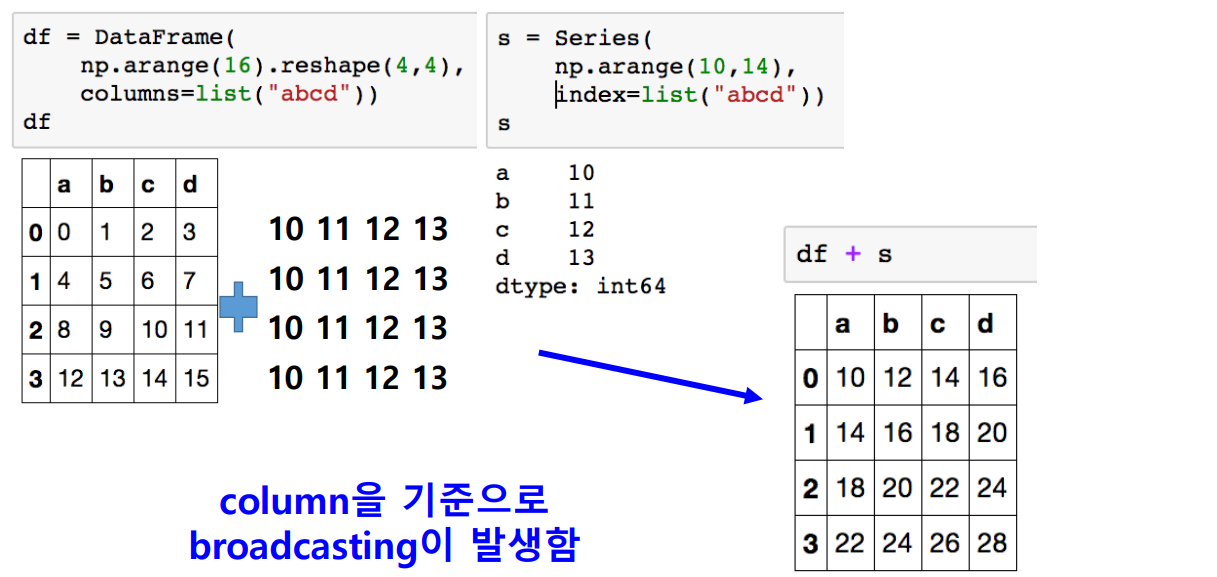
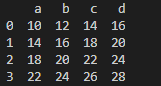
Broadcasting
numpy에서 array와 scalar 사이의 연산이 가능했듯이, Series와 DataFrame 간의 연산 역시 가능합니다. 이때는 column 방향으로 broadcasting이 일어납니다.
Lambda for Series
lambda는 함수를 한 줄로 표현하는 기법입니다. 주로 square 등의 간단한 함수를 표현할 때 사용합니다. Python도 lambda를 지원하는데, VS Code에서는 어째서인지 람다를 전부 def 방식으로 바꿔버립니다..

뭐 아무튼 우리에게 중요한 것은 Series에도 lambda를 적용할 수 있다는 점입니다.
# map with series: can applicate map() with pd.Series!
s1 = pd.Series(np.arange(10))
print(s1.map(lambda x: x**2))map()의 매개변수에 람다 식을 넣으면 됩니다. 위에서 lambda x: x**2 부분을 람다 식이라고 부릅니다.

(참고로 Python에서 map()은 iterable의 각 원소에 함수를 적용시킨 결과를 반환하는 함수입니다)
map()의 용도는 아직 끝나지 않았습니다. series의 데이터를 map()으로 바꿀 수도 있습니다.
z = {1: 'a', 2: 'b', 3: 'c'} # pair of (index, value)
print(s1.map(z))
(index, value) 쌍을 담고 있는 dict를 이용하여 series의 데이터를 바꾼 모습입니다. value가 지정되지 않은 index에는 NaN이 저장되었습니다.
replace()
이 내용은 매우 중요하기 때문에 따로 분리했습니다.
아래의 데이터를 예시로 봅시다.
df = pd.read_csv(
'https://raw.githubusercontent.com/rstudio/Intro/master/data/wages.csv')
print(df.head(5))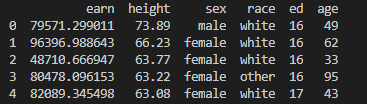
sex의 값을 남자는 0, 여자는 1을 갖게 바꾸고 싶습니다. 그럴 때는 replace()를 사용하면 됩니다.
print(df['sex'].replace({"male": 0, "female": 1}).head())
dict를 사용하여 값을 매칭시켰습니다.
다른 방법으로, "target to result" 방법을 사용할 수 있습니다(이름은 제가 임의로 붙였습니다).
df.sex.replace(
['male', 'female'], # target list
[0, 1], # conversion list
inplace=True) # apply changes to original data
replace()는 데이터를 변환할 때 가장 자주 이용되는 함수입니다. 기억합시다.
apply() for DataFrame
map()은 column 하나에만 함수를 적용했었죠? apply()는 모든 Series에 대해 함수를 적용합니다. 각 series에 대해 map()을 적용한다고 봐도 될 것 같네요. 간단한 예시를 보며 이해합시다.
df_info = df[['earn', 'height', 'age']]
# apply: applicates function to each column
f = lambda x : x.max() - x.min()
print(df_info.apply(f))
f()는 어떤 데이터에서의 최댓값과 최솟값의 차이를 반환합니다. 이러한 f()가 'earn', 'height', 'age' 각 column에 적용된 결과를 볼 수 있습니다.
비슷한 함수로 applymap()이 있습니다. 이 함수는 각 원소에 대해 함수를 적용합니다. applymap()을 사용하면 이런 장난도 칠 수 있습니다.
print(df_info.applymap(lambda x: return -x).head(5))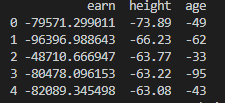
Pandas Built-in Functions
pandas는 DataFrame에 적용할 수 있는 여러 기본 함수를 제공합니다. 오늘은 두 개만 알아보도록 하겠습니다.
describe()
이 함수는 numeric data의 통계 요약치를 보여줍니다. 평균, 표준편차 등의 값을 제공합니다.

unique()
Series에 있는 값을 중복 없이 모두 알고 싶다면 unique()를 사용하세요.
# unique: sets of values in series
print(df.race.unique())
numpy array를 이용하여 약간만 응용하면, 각 값에 index를 부여할 수도 있습니다. 이건 그냥 덤으로 보고 가시면 됩니다.
print(np.array(dict(enumerate(df.race.unique())))) # index each unique values
오늘은 Pandas의 기본 기능에 대해 알아봤습니다. 반드시 코드를 직접 입력하며 공부하시길 바랍니다.
다음에는 Pandas를 이용하여 데이터를 정제하는 여러 방법을 알아보도록 하겠습니다.
'Secondary > Python' 카테고리의 다른 글
| static method, class method, abstract method (0) | 2023.03.01 |
|---|---|
| Data Cleansing (0) | 2020.01.15 |
| matplotlib (0) | 2020.01.12 |
| Pandas (2) (0) | 2020.01.10 |
| Numpy - Numerical Python (0) | 2020.01.05 |



