
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 백준
- NGINX
- 코드포스
- architecture
- textfield
- TEST
- androidStudio
- boj
- 쿠링
- pandas
- Codeforces
- Python
- 암호학
- MiTweet
- Rxjava
- GitHub
- relay
- ProGuard
- 코루틴
- Coroutines
- Hilt
- Compose
- android
- Coroutine
- livedata
- Gradle
- MyVoca
- AWS
- 프로그래머스
- Kotlin
- Today
- Total
이동식 저장소
Pandas (2) 본문
오늘은 Pandas를 이용하여 raw data를 여러 형태로 정제하는 법에 대해 알아보겠습니다.
import pandas as pd
import numpy as np데이터 준비
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'Kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3, 4, 1, 1, 2, 4, 1, 2],
'Year': [2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017],
'Points': [876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690]}
df = pd.DataFrame(ipl_data)
print(df)
Groupby
데이터를 특정 기준으로 grouping합니다. SQL의 group by~와 같은 기능입니다. 묶은 그룹별로 연산(sum, avg 등)을 적용할 수 있습니다.
print(df.groupby('Team')['Points'].sum()) # group -> apply -> combine result위 코드는 Team으로 그룹을 묶어서 Points의 sum을 구한 코드입니다.

Hierarchical Index
위의 데이터를 다시 보시면, 하나의 팀에 대해 여러 연도의 데이터가 존재하는 것을 볼 수 있습니다. 'Team'과 'Year' 둘 다 묶고 싶다면 어떻게 해야 할까요?
# hierarchical index: group using two or more columns
result = df.groupby(['Team', 'Year'])['Points'].sum()
print(result)
리스트에 묶고 싶은 column name을 넣어서 groupby()에 매개변수로 주면 됩니다. 깔끔하게 정리됐죠?
출력된 결과를 보면, 데이터가 Team으로 한번 나눠진 후 Year로 다시 한번 분류됩니다. 이처럼 여러 개의 인덱스를 이용하여 데이터를 분류하는 것을 Hierarchical Index라고 합니다.
인덱스의 순서를 바꿀 수도 있습니다. 위에서 Year로 먼저 분류하고 싶다면 Index level을 바꿔주면 됩니다.
# change index level
print(result.swaplevel())
위에서 묶은 Index별로 연산을 적용할 수 있습니다. 예를 들어 Team별로 모든 연도의 점수 합을 구할 수도 있고, 각 연도마다 모든 팀의 점수 합을 구할 수도 있습니다. 0부터 시작하는 Index level을 지정해 주면 됩니다.
# operations: basic operation by index level
print(result.sum(level=0)) # Team
print(result.sum(level=1)) # Year
Unstack
Hierarchical Index로 묶은 데이터를 행렬로 바꾸고 싶다면 unstack해 주면 됩니다.
# unstack: group -> matrix
print(result.unstack())
없는 데이터는 NaN으로 채워져 있네요.
Extract Grouped Data
DataFrame으로부터 group된 데이터 객체를 얻을 수도 있습니다. for문을 이용하여 각 그룹의 이름과 데이터를 각각 str, DataFrame 타입으로 얻을 수 있습니다.
# extract grouped datas
grouped = df.groupby('Team')
for name, data in grouped:
print('=== ' + name + ' ===')
print(data)
데이터를 그룹으로 묶는 이유는 본질적으로 분류를 하기 위해서입니다. 분류한 데이터마다 어떤 연산을 적용하여 통계치를 얻고 싶을 수도 있겠죠. 이제 그룹 데이터에 적용할 수 있는 다양한 연산에 대해 알아봅시다.
Group 1 - Aggregation
각 그룹마다 주어진 함수를 적용합니다. 미리 정의된 함수 이름을 줄 수도 있고, 람다식을 줄 수도 있습니다.
# group 1: aggregation
print(grouped.agg(sum))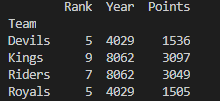
생각해 보니 Rank와 Year를 더하는 건 별로 의미가 없는 것 같습니다. Points에만 연산을 적용할 수도 있습니다. 심지어 여러 연산을 한꺼번에 적용할 수도 있습니다.
print(grouped['Points'].agg([np.sum, np.mean, np.std])) # apply two or more functions at one column
numpy를 이용하여 점수의 합, 평균, 표준편차를 구해봤습니다.
Group 2 - Transform
주어진 데이터를 어떤 식에 따라 변형할 수 있습니다. 예를 들어 각 데이터에 대한 표준정규분포에서의 Z값을 구하고 싶을 수도 있겠죠. 그럼 그냥 하면 됩니다. (???)
# group 2: transform
def score(x): return (x-x.mean())/x.std()
print(grouped.transform(score))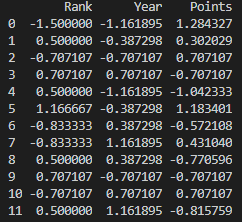
transform() 함수는 각 데이터마다 주어진 함수를 적용하여 값을 변형합니다.
Group 3 - Filter
어떤 조건에 맞는 데이터만 찾을 수 있습니다. filter()에 함수를 넘겨주면 됩니다.
# print groups that match the condition
print(grouped.filter(lambda x: x.Points.max() > 850))위 코드는 점수의 최댓값이 850점보다 큰 그룹의 데이터를 출력합니다.

Merge
여러 이유에 따라 데이터를 분리해야 하는 경우가 있습니다. 그런데 필요에 따라서는 데이터를 합쳐서 봐야 할 때도 있죠. DataFrame를 merge하여 데이터를 합칠 수 있습니다.
먼저 데이터를 준비합니다.
raw_data = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_score': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
df_a = pd.DataFrame(raw_data, columns=['subject_id', 'test_score'])
print(df_a)
raw_data2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Bitsan']}
df_b = pd.DataFrame(raw_data2, columns=[
'subject_id', 'first_name', 'last_name'])
print(df_b)
두 데이터에 공통으로 존재하는 column이 subject_id이므로, id를 기준으로 데이터를 합쳐야 합니다. 이때 한쪽에만 존재하는 데이터는 합쳐지지 않습니다. 즉 subject_id=4인 데이터는 합쳐지지만, subject_id=1인 데이터는 df_a에만 존재하기 때문에 합쳐지지 않습니다.
print(pd.merge(df_a, df_b, on='subject_id')) # merge by subject_id

이것은 SQL의 join(정확히는 inner join) 연산과 같습니다.
그런데 데이터 A에서는 학번을 '학번' column에 저장했지만, 데이터 B에서는 '학생번호'로 저장할 수도 있죠. 데이터의 본질은 같지만 이름이 다른 경우입니다. 이때는 합치는 기준이 되는 column name을 각각 줘야 합니다.
# if column names are different
print(pd.merge(df_a, df_b, left_on='subject_id', right_on='subject_id'))
left_on과 right_on에는 각각 df_a에서와 df_b에서의 column name을 명시해야 합니다. 물론 데이터의 의미가 다르면 안 되겠죠?
* 아래의 내용은 SQL 구문을 아는 분에 한하여 읽으시기 바랍니다.
Data Persistent with Pandas
DB로부터 실제로 데이터를 불러와서 여러 작업을 해 봅시다. 우선 링크를 클릭하여 데이터 파일을 다운로드하고, 작성중인 코드 파일과 같은 폴더에 저장하세요.
우선 DB 파일을 열고, 데이터를 간단히 읽어 봅시다.
conn = sqlite3.connect("flights.db")
cur = conn.cursor()
cur.execute("select * from airlines limit 5;")
results = cur.fetchall()
print(results)1. DB 파일을 open하여 conn 변수에 정보를 저장했습니다.
2. 연 파일에서 cursor를 가져옵니다.
3. 커서에 SQL query를 넘겨줍니다. query를 실행하기 위해서는 fetchall() 함수를 실행해야 합니다.
4. query에 대한 response를 받아서 출력합니다.

그런데 결과가 너무 읽기 힘듭니다. DataFrame 형식으로 보여주면 좋을 텐데..
그런 여러분을 위해 Pandas는 query를 실행하고 결과를 DataFrame으로 반환해 주는 함수를 제공합니다.
# load data from DB
df_airplanes = pd.read_sql_query("select * from airlines;", conn)
print(df_airplanes)read_sql_query() 함수에 SQL 구문과 커서를 넘겨주면 DataFrame이 반환됩니다.

원하는 대로 데이터를 얻었습니다. 이제 이것저것 출력해 봅시다.
df_airports = pd.read_sql_query("select * from airports;", conn)
df_routes = pd.read_sql_query("select * from routes;", conn)
print(df_airports)
print(df_routes)
Pandas를 이용하여 데이터를 처리하는 방법을 알아봤습니다. 사실 Pandas 단독으로 공부하기보다는 필요한 때마다 찾아서 보는 게 좋은 듯 합니다.
다음 글에서는 Python의 대표적인 데이터 시각화 도구인 matplotlib에 대해 공부해 보겠습니다.
'Secondary > Python' 카테고리의 다른 글
| static method, class method, abstract method (0) | 2023.03.01 |
|---|---|
| Data Cleansing (0) | 2020.01.15 |
| matplotlib (0) | 2020.01.12 |
| Pandas (1) (0) | 2020.01.09 |
| Numpy - Numerical Python (0) | 2020.01.05 |



